.png)


I den moderne digitale alderen er data drivstoffet, og dataplattformen fungerer som motoren. Som min kollega Peter Ryen Bull skrev i Hvorfor dataplattform? | Miles AS, vil de som lykkes med å etablere en robust dataplattform oppnå et betydelig konkurransefortrinn.
En dataplattform er imidlertid mer enn bare teknologi - det er et dynamisk økosystem der organisering, eierskap og tekniske valg er uløselig knyttet sammen. Derfor er det kritisk å forstå helheten som binder disse elementene sammen. Denne artikkelen tar deg med på et konseptuelt dypdykk i de ulike komponentene som utgjør dataplattformens anatomi. Vi utforsker de strategiske valgene som er med på å definere dataplattformen, og de arkitektoniske valgene som sikrer at data hentes og transformeres fra råmateriale til handlingsklare dataprodukter.
Fugleperspektivet: Komponentene i en dataplattform
En dataplattform består i hovedsak av ni ulike komponenter med deres respektive underkomponenter som illustrert i bildet under
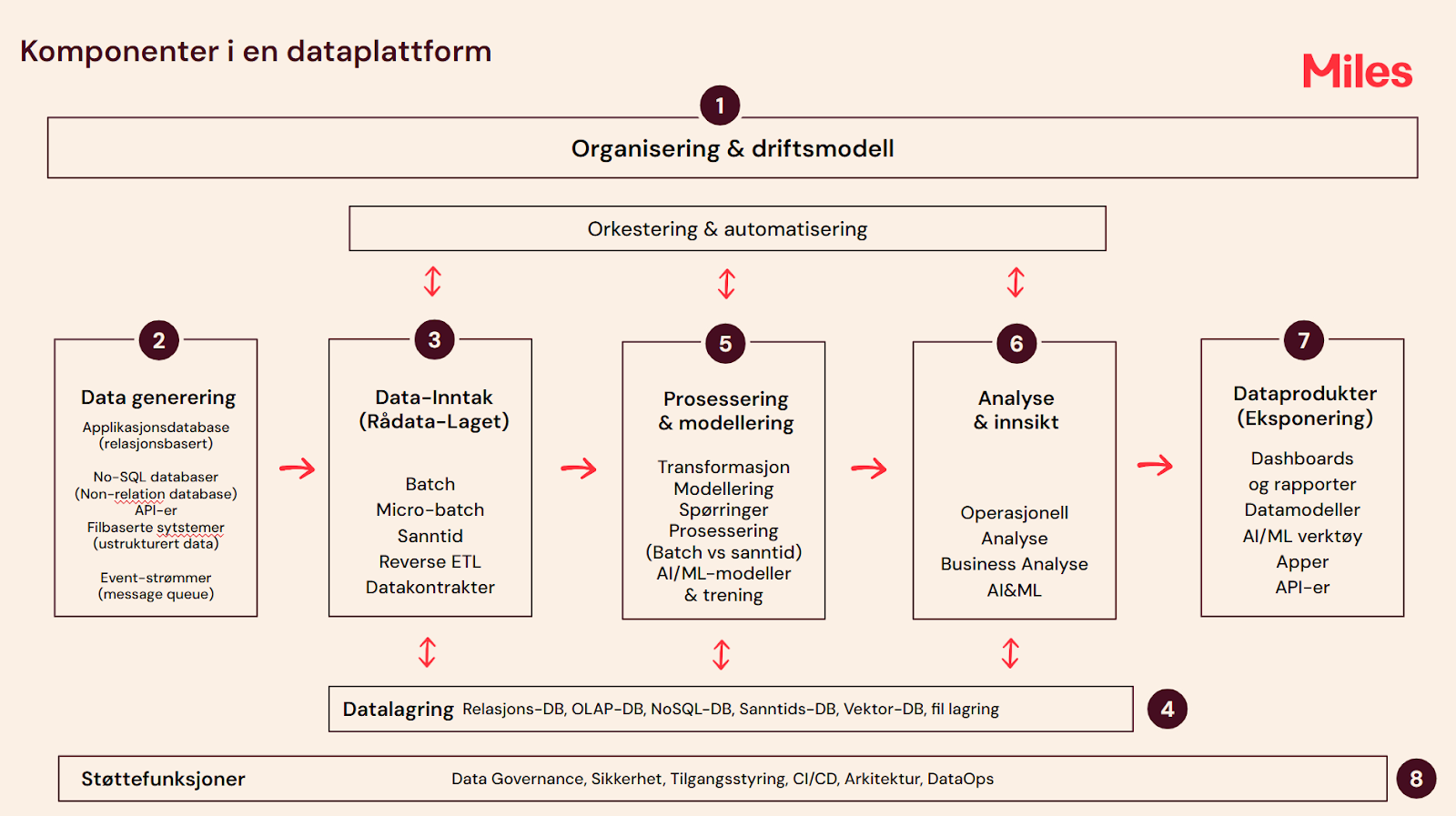
1. Organisering og Driftsmodell
Før vi skriver en eneste linje med kode, må de fundamentale strategiske beslutningene være på plass. En dataplattform kan ikke eksistere i et vakuum; den må være forankret i selskapets overordnede datadrevne strategi. Uten et slikt langsiktig strategisk perspektiv og en ledelse som investerer i dette over tid, vil plattformen aldri nå sitt fulle potensial. Det blir som å kjøpe en Ferrari bare å kjøre fem minutter til matbutikken hver dag.
En stor feil er å anta at en god dataplattform bare handler om teknologi, og ikke mennesker og prosesser. Dataplattformen er bare så god som teamet som bygger den, og en struktur designet for et team på to vil uunngåelig kollapse når det skal skaleres til tjue eller mer. En slik modell krever et klart eierskap for dataflyten fra kilde til forbruk, og tydelige ansvarsområder. Samtidig kreves det en robust kultur- og kompetansemodell.
- Har vi ressurser som forstår både teknologi og forretning?
- Har vi kompetansen som kreves for å operere en moderne, skalerbar plattform effektivt?
- Skal vi ha et sentraliserte dataplattformteam og desentraliserte produktteam?
Dette er et av mange spørsmål der klare svar på disse er avgjørende for å sikre at dataplattformen utvikler seg fra å være en teknisk løsning til et kontinuerlig strategisk verdikilde.
2. Datagenerering
Data starter alltid ved kilden, og her møter vi den første arkitektoniske utfordringen: Data er sjelden enhetlig. Kildedata genereres i et bredt spekter av systemer:
- Applikasjonsdatabaser (Strukturerte data og relasjonsdatabaser)
- No-SQL databaser
- Filbaserte systemer (Ustrukturert data)
- API-er
- Sanntids Event-strømmer (message queue).
Dette mangfoldet krever at vi tidlig i prosessen identifiserer kildene for hvert domene. Utover å identifisere kilden, er det i dette steget avgjørende å forstå dataets natur, volum og oppdateringsfrekvens. Kun ved å kartlegge kilden og dens begrensninger, kan man ta de riktige valgene i neste lag for å sikre en effektiv og stabil dataflyt.
3. Datainntak
Datainntak er det første tekniske laget i dataplattformen. Det fungerer som mottakssenteret for alle innkommende data, og er avgjørende for å sikre den tekniske og strukturelle kvaliteten før transformasjon.
Valg av inntaksmodus er sentralt i dette laget, der vi vurderer ulike former avhengig av use-case.
- Batch (kosteffektivt for store, tidsuavhengige volum)
- Micro-batch (et praktisk kompromiss mellom hastighet og kostnad)
- Sanntid (streamet data for umiddelbar verdi).
- CDC (Change Data Capture)
Her må vi stille oss spørsmålet: Når er sanntid virkelig nødvendig, og når er Micro-batch/Batch et tilstrekkelig og mer kostnadseffektivt alternativ? Ofte er Micro-batch/Batch tilstrekkelig for å møte forretningsbehov, samtidig som det reduserer kompleksiteten betraktelig. Samtidig er det viktig å velge et alternativ som unngår friksjon eller nedetid for kildesystemene.
Utover flyt er etableringen av Datakontrakter (Schema/Kontrakter) en veldig viktig funksjon. Dette er den formelle avtalen mellom produsent (generering) og konsument (inntak) om dataformat og kvalitet. Dette er viktig for dataplattformens stabilitet. Et viktig spørsmål her er: Hvilken teknologi og praksis sikrer at datakontraktene blir overholdt og at endringer i kildesystemet ikke bryter nedstrøms prosesser? Min gode kollega Peter Bull har skrevet en god artikkel om dette, der han diskuterer viktigheten av datakontrakter Datakontrakter | Miles AS
Dette laget håndterer også tekniske prosesser som Reverse ETL, som nå er en voksende trend. Men når vi sender data tilbake mot operasjonelle systemer eller SaaS-verktøy via Reverse ETL, må vi vurdere: Hva er de sikkerhetsmessige implikasjonene av å sende behandlet data tilbake til kildesystemene? Svaret på dette definerer også grensene for dataplattformens operasjonelle rekkevidde.
4. Datalagring
Datalagring er fundamentet dataplattformen er bygget på. En moderne dataarkitektur baserer seg sjelden på én enkelt teknologi, men krever en kombinasjon av lagringsløsninger for å matche forretningsbehov og dataens formål. Dette kan blant annet innebære å utnytte det kostnadseffektive volumet i Data Lake (fil lagring) for rådata, kraften i Relasjons-DB for strukturerte forretningsmodeller, fleksibiliteten for ustrukturerte data, og spesialiseringen i Vector-DB for å støtte avanserte AI-applikasjoner.Her eksisterer det mange ulike teknologier en kan velge mellom for å løse de ulike behovene.
Viktige spørsmål en bør stille seg er blant annet:
- Skalerbarhet - Klarer lagringssystemet å skalere med økende datamengder uten at det påvirker ytelsen?
- Tilgjengelighet og sikkerhet - Hvordan sikrer lagringssystemet at vi har kontinuerlig tilgang til data? Hvordan er mekanismene knyttet til kryptering, sikkerhet og katastrofehåndtering?
- Kostnadsoptimalisering - Hvordan valideres og flyttes data mellom de ulike lagene for å oppnå kostnadsoptimalisering? Hvordan er prismodellen til lagringsteknologien?
Like viktig som selve lagringen er håndtering av metadata og sporbarhet (Lineage). Uten dette blir datalagret en uoversiktlig sump. Dette er viktig for å sikre at brukere kan finne, forstå og stole på dataene, uavhengig av hvor de er lagret. Det fungerer også som en sentral kilde for metadata, dokumentasjon og bygger tillit hos konsumentene ved å gi innsyn i hvordan data har blitt behandlet gjennom hele livsløpet.
5.Prosessering og modellering
Dette er hjertet av dataplattformen og hvor den virkelige verdiskapningen skjer. Her omdannes rådata til forretningslogikk gjennom transformasjon (rensing og berikelse) og modellering (strukturering av data).
Et sentralt valg er graden av modellering. Viktige spørsmål en bør stille er blant annet: Hvilket modelleringsvalg (f.eks. Data Vault, Star/Snowflake schema, One Big Table) gir den beste balansen mellom fleksibilitet og ytelse for våre forretningsbehov? Valget her påvirker alt nedstrøms, fra hvor raskt analytikere kan hente data, til hvor smidig nye kilder kan integreres.
En annen utfordring er Batch vs. Sanntids prosessering. Batch-prosessering som utnytter kraftige SQL- og Spark-baserte spørringsmotorer, er ideelt for å behandle store datamengder på bestemte tidspunkter. Denne tilnærmingen er tilstrekkelig for de aller fleste analytiske behov, som periodisk rapportering, historisk analyse og nattlige oppdateringer. I motsatt ende finner vi Strømmeprosessering, som er nødvendig for scenarier som krever analytisk innsikt i nær sanntid og med minimal forsinkelse. Dataplattformen må kunne håndtere begge deler.
Til slutt er ML-integrasjon avgjørende for dataplattformen. Dette laget har ansvaret for å tilrettelegge feature-sett for maskinlæring som krever omfattende prosessering. Her er det viktig å levere rådata og transformeringslogikk til AI/ML-team, samtidig som vi sikrer governance og sporing.
6. Analyse og Innsikt
Dette laget er dedikert til å transformere prosessert data til direkte handlingsbar innsikt. Her flyttes fokuset fra hvordan data er bygget til hvordan data blir brukt. Her er fokuset på brukeradferd og å tilby et bredt spekter av verktøy og grensesnitt som dekker de ulike behovene til analytikere, Data Scientists og forretningsbrukere.
Dette innebærer alt fra:
- Operasjonell Analyse (for daglig styring)
- Business Analyse (for strategiske rapporter)
- AI/ML-modeller (for prediksjon).
Her er det samtidig viktig å sikre konsistent semantikk og tilgangskontroll når data eksponeres gjennom flere ulike analyseflater.
En god indikator på en vellykket datastrategi er imidlertid evnen til å demokratisere data og bygge tillit blant forbrukerne. Med et så variert forbrukslandskap, og behovet for å støtte ulike verktøy (BI, SQL, ML), må vi spørre: Hvordan kan vi sikre konsistent semantikk og tilgangskontroll når data eksponeres gjennom flere ulike analyseflater? Her kan et felles semantisk lag sikre at alle brukere – uansett om de ser på et dashboard eller trener en ML-modell – jobber med nøyaktig de samme definisjonene. Å oppnå denne konsistensen er avgjørende for å etablere dataplattformens troverdighet og operasjonell verdi.
7. Dataprodukter
Mens Analyse- og Innsikt-laget beviser plattformens operative verdi, er dataprodukter den endelige leveransemodellen for den verdien. Et Dataprodukt er en garantert leveranse definert av eierskap, kvalitet og SLA. Dette er essensielt når data krever kryss-konsolidering – altså sammenslåing fra to eller flere kilder. I slike komplekse tilfeller må vi spørre: Hvem eier og vedlikeholder data som er sammensatt fra mange forskjellige kilder?
Verdien eksponeres deretter gjennom det mest effektive grensesnittet. Dette betyr at dataproduktet kan opprettes på flere måter:
- Gjennom rapportering og dashboards
- Selvbetjeningsverktøy for analyse
- API-er og andre tjenester som integreres direkte i applikasjoner.
Denne eksponeringen muliggjør reell datademokratisering, da sluttbrukerne får tilgang til troverdige data uten å måtte forstå den underliggende kompleksiteten. Her må en vurdere: Har vi korrekt grensesnitt (API, SQL, Fil) for å sikre at konsumenten får dataen de trenger på den mest effektive måten? Ved å tilby et slikt mangfold av eksponeringer fra standardiserte KPI-er til skreddersydde applikasjoner, sikrer plattformen at verdien når alle hjørner av virksomheten.
8. Støttefunksjoner
Plattformens stabilitet, skalerbarhet og tillit hviler på en rekke tette støttefunksjoner. Dette er disiplinene som sikrer at plattformen ikke bare leverer data, men garanterer for dataens opprinnelse, kvalitet og lovlighet.
Sentralt står Data Governance, som definerer tydelige beslutningsstrukturer og ansvarsfordeling. Ettersom datamengden og plattformen skalerer, blir det viktig å etablere et felles begrepsapparat og spore data. Governance-disipliner omfatter blant annet:
- Metadatahåndtering
- Data Lineage (sporing av data fra kilde til konsum)
- Data Discovery for å sikre at brukere kan finne og stole på dataene.
Dette arbeidet er også knyttet til orkestrering og DataOps. Gjennom Kontinuerlig Integrasjon (CI) og Kontinuerlig leveranse (CD) sikres det at kode er i en konstant tilstand av integrasjon, testing og leveranse.
Til slutt er sikkerhet og tilgangsstyring ikke forhandlingsbart. Dette handler om å beskytte data mot uautorisert tilgang og å sikre compliance. Moderne plattformer benytter gjerne en samlet sikkerhetsplattform for å standardisere og automatisere sikkerhetsregler på tvers av ulike skymiljøer (som Azure og Google), og sikrer at tilgang konsekvent er basert på behov. Disse funksjonene er plattformens skjold og kart; de muliggjør smidig innovasjon innenfor trygge rammer.
Konklusjon: Bygg plass til vekst
Som denne dypdykken i dataplattformens anatomi viser, er det mange kritiske komponenter og strategiske spørsmål som en må adressere. Utfordringen kan virke overveldende, men veien til en verdifull dataplattform ligger ikke i å bygge alt på én gang.
Vårt råd er å starte med et begrenset antall datakilder og bygge dataplattformen rundt noen få komplette datastrømmer som leverer full funksjonalitet fra kilde til forbruk. Fokuset ligger på å levere én eller to veldefinerte dataprodukter fra ende til ende. Dette lar deg etablere de viktigste byggesteinene - som datakontrakter, eierskap og de sentrale orkestrering-prosessene, i et kontrollert miljø. Etter hvert som tilliten og kompetansen vokser, kan du utvide den funksjonelle dekningen, skalere til flere kilder, og gradvis utvide tilbudet av Dataprodukter. Ved å velge en trinnvis, strategisk tilnærming sikrer du at dataplattformen ikke blir et byråkratisk monster, men et dynamisk økosystem som kontinuerlig skaper forretningsverdi.
